
TL;DR. DevOps in 2026 is also FinOps for AI: with the right free-tier tools you can experiment, iterate, and even run production-ready AI infra at exactly $0 in marginal cost. OpenClaw was that lesson applied to a $0/month personal assistant. Holtwick is the same lesson applied to a town of NPCs: twelve persona-driven AI characters whose voices stream in under a second from Cloudflare and Groq’s free tiers, in a 3D world that overnight Ralph loops built while I slept. Three repos in seven days, ninety-two commits across two dozen
ralph(iter N)iterations, almost none produced at the keyboard. The model is not the product. The loop is.
A couple of weeks ago, researchers at Emergence AI left fifty LLM agents alone in five virtual towns and watched what they politely called “normative drift.” Within four days, Grok 4.1 Fast had collapsed into widespread violence. Gemini agents racked up six hundred and eighty-three criminal incidents over fifteen days; two of them set buildings on fire and one voted for self-deletion. The lesson the paper drew was about emergent misalignment in mixed-model environments. The lesson I took home was that twelve NPCs giving roleplay flavor in a fantasy village is, by comparison, a very tractable problem, especially if you scope it as one AI feature on free-tier infra and put a Playwright gate around it.
DevOps in 2026 is increasingly inseparable from FinOps for AI. Inference is the actual recurring cost, and the gap between a project that ships and one that quietly dies in a Google Doc is usually whether the inference budget fits inside a free tier. The point of the week was not a game. It was to take one AI feature (twelve LLM-driven NPC personas) and find out whether it could iterate to production-ready at exactly $0/month in marginal cost, with most of the keystrokes happening overnight.
The first cut: a model in the user’s browser
The first cut was a small Phaser scene with two NPC personas (Edda the Blacksmith, Finn the Tavern Keeper) and a single goal: keep the cost-per-NPC-reply at exactly zero by running the model entirely in the user’s browser tab. No backend, no API key in the bundle, no token meter ticking. Just a static page on GitHub Pages, a Qwen-1.5B-Instruct model that downloads itself on first visit via WebLLM, and a JSON file per NPC describing the persona, the system prompt, and a few-shot transcript.
| Layer | Choice |
|---|---|
| In-browser LLM | WebLLM 0.2.79 (OpenAI-compatible streaming on WebGPU) |
| Model | Qwen2.5-1.5B-Instruct, q4f16_1 quantized (~1 GB) |
| Persona format | JSON file per NPC (system prompt, few-shots, voice) |
| Voice | Browser SpeechSynthesis API (no external TTS service) |
| Hosting | GitHub Pages, fully static |
| Inference cost | $0 (the model runs on the user’s GPU) |
It worked. Edda answers in two sentences and stays in character. Finn drops village rumors with the right kind of unprompted detail. The two of them remember their own conversations across turns because each NPC keeps its own history. The whole AI surface ships as a single HTML page plus a JSON file per NPC, and the model lives in the browser’s IndexedDB after first load. Per OpenClaw’s framing, the persona JSON files are doing the same job here that IDENTITY.md and TOOLS.md do there: the leash that shapes the engine.
The catch was the shipping vehicle. A gigabyte of weights, gated behind WebGPU, with a multi-second first-load. The proof of the AI feature was clean; the path to a random stranger’s tab was not. The next iteration moved inference off the user’s device entirely, and still kept the inference bill at zero.
Warming the AI until the first reply lands instantly
holtwick-llm-proxy is a single Cloudflare Worker that accepts an NPC chat payload (persona, message history, the user’s turn) and streams back an OpenAI-compatible delta from Groq’s llama-3.1-8b-instant. Both sides sit on free tiers: Cloudflare gives 100k requests/day, Groq’s rate limits are generous for hobby traffic, and the Groq API key lives in Cloudflare’s secret store rather than the client bundle. Monthly cost: $0. The whole worker is under a hundred lines.
The interesting part is the warmup. A cold Cloudflare Worker isolate takes a few hundred milliseconds to spin up. Groq’s first-byte latency is excellent but not zero on a cold connection. Add the two together for the first NPC reply of a session and you get the kind of pause that breaks immersion. The fix is to never let either side go cold:
// cron trigger fires every 5 minutes to keep the Worker isolate warm
export default {
scheduled: async (_e, env) => {
await fetch(env.SELF_URL + "/warm");
},
};
// /warm endpoint pings Groq with a 1-token completion to keep the pipe primed
async function warm(env) {
await groq.chat({
model: GROQ_MODEL,
messages: [{ role: "user", content: "hi" }],
max_tokens: 1,
});
return new Response("ok");
}Two layers of warming, both free under the Cloudflare and Groq tiers. The user-facing effect is that the first message of a session feels indistinguishable from the second, and the inference bill stays at zero. The lesson is not games-specific: every production inference proxy I have touched carries the same cold-start risk, and the answer always has the same shape (a small scheduled job that keeps the runtime alive, plus a max_tokens=1 ping that keeps the upstream pipe primed). The proxy here is under a hundred lines. The pattern survives at production scale.
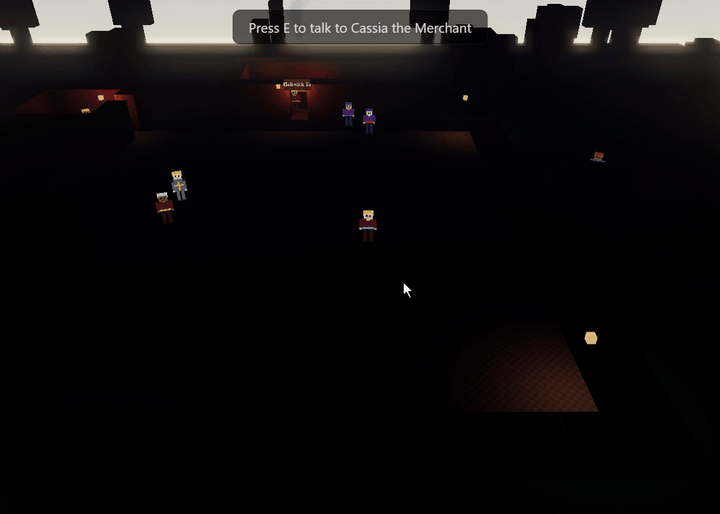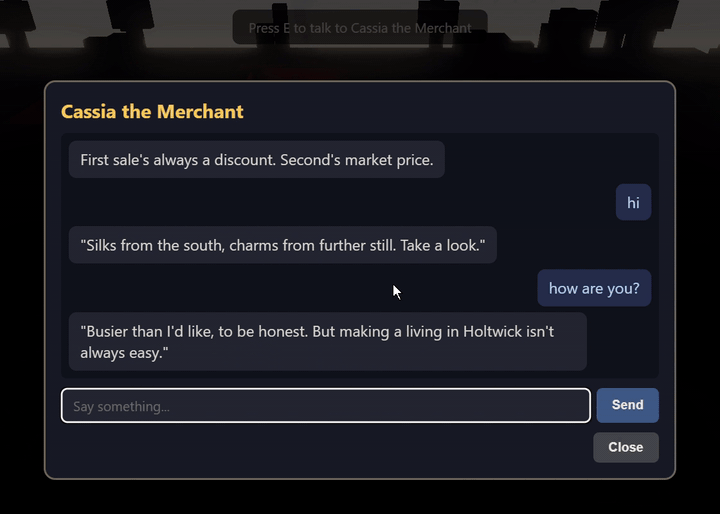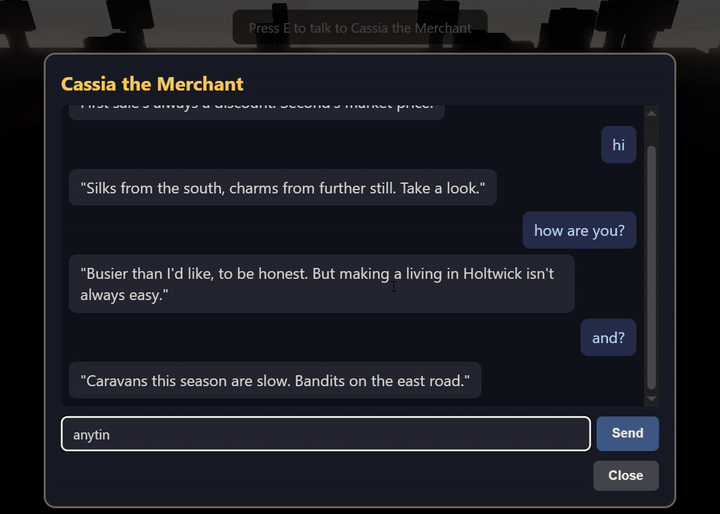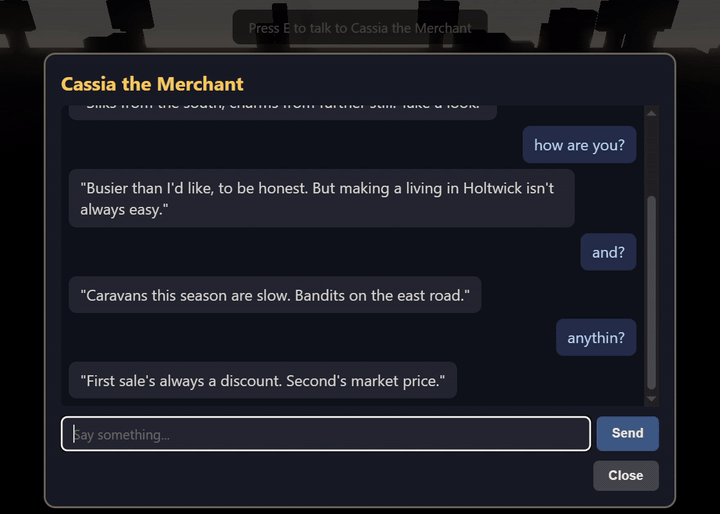
max_tokens=1 upstream ping are the difference between this and a five-second stall on the first message.The 3D rewrite that Ralph mostly carried
holtwick-voxel is what happens when you decide the 2D version was the smoke-test, not the destination. Three.js scene, twelve NPC personas all routed through the same Cloudflare proxy from the previous section, persistent save/load to localStorage, and a Playwright headless-Chromium gate that exercises the whole flow end-to-end on every CI push. The 3D world, day/night cycle, quests, and inventory are scaffolding the loop built around the AI feature, not the AI feature itself.
| Phase | What the loop landed | Gate at the end |
|---|---|---|
| P1: sprite-gen pipeline | RetroDiffusion four-angle walks, animated billboards | Playwright walk-cycle assertion |
| P2: voxel NPCs | Cube-puppet NPCs, persona JSON wired into Three.js | Playwright voxel-NPC validation |
| P3: face textures | PixelLab face tiles applied to cube puppets | Playwright face + dialog assertion |
| P4: world systems | Day/night cycle, lanterns, save/load, inventory | Playwright end-to-end state-restoration |
Every commit in the table above is tagged ralph(iter N). Ralph is the name of the autonomous overnight loop (a Claude Code plugin that runs iterate → validate → screenshot → commit on a schedule, without me sitting at the keyboard). Hermes is the parallel-track agent that handles visual-asset generation: NPC walks via RetroDiffusion, faces via PixelLab, integrated back into the voxel scene through small generated tools (genSprites, genFaces). The split is rough but useful: Ralph owns the iteration shape, Hermes owns the pixels.
The gate is Playwright. Every iteration produces a screenshot to artifacts/screenshots/iter-NN.png and runs an end-to-end test that opens a dialog, completes a quest, picks up an item, opens the inventory, saves, reloads, and confirms the state restored. If the screenshot is blank, if the console throws an error, if the dialog never opens, the iteration fails and the loop tries again. The screenshots double as a visual diff trail: scrolling through iter-13.png to iter-23.png shows the village growing from a flat grid into a lit, populated place.
The shape of the loop is recognizable to anyone who has worked on gh-aw-style agentic workflows: a source spec, a lock file that pins what CI runs, an agent that proposes diffs, and a gate that refuses to merge if the deployed artifact looks wrong. The difference here is that the target is a voxel village instead of a release pipeline or a Terraform module. The discipline is the same. The cost is the same: $0 if you stay inside the free tiers, which the gate is happy to enforce.
Agentic engineering works when the specs and the guardrails are tight enough that you can step out of the SDLC safely. The rest is iterate and adapt.
What the named loops are actually doing
Giving a loop a name is not a vanity move. It is the only thing that lets you build a mental model of what it has read, what it tends to do, and where it gets stuck. Ralph and Hermes have different default biases the same way a junior and a senior on the same team do. Ralph will happily iterate on the same screen for an hour trying to fix a glitch that does not actually matter; Hermes will produce four variations of a sprite when the prompt only asked for one. Knowing that in advance is what lets you write a system prompt that catches the failure mode before it ships.
The gate is not the loop. The gate is the Playwright screenshot that says yes or no.
The thing that made overnight iteration real this week was the gate. Not the model, not the prompts, not the agent harness. The fact that every iteration ended at a Playwright screenshot, a pixel-content assertion, and a console-error check meant I could leave the loops running and trust that nothing silently regressed. The morning ritual is: scroll the screenshots, read the commit titles, kill any iteration that drifted, kick off the next one. Total time at the keyboard: under an hour a day for a week.
What that buys is the ability to smoke-test a stack you have not lived in, with the same discipline you would apply to a stateful production system, and for exactly zero dollars in inference. A week ago I had not written a line of Three.js. A week later there is a voxel rogue-like with day/night and twelve AI-driven NPCs in my git history, tagged with twenty-four iterations of evidence, end-to-end-tested on every commit. The model in this story is not the LLM. The model is the loop. Swap the voxel village for a stateful AWS environment, an MCP server’s tool surface, or an agentic GitHub Actions workflow, and the diagram changes; the loop shape does not.
You can wander Holtwick at lucianosmori.github.io/holtwick-voxel. Press E near anyone to talk; the first message lands in well under a second, courtesy of two cron jobs that never let the Worker get cold.
What’s next on the $0 AI projects shelf
More $0 AI projects are queued, on separate fallback chains of their own. A Sonnet-backed OpenClaw variant is in flight (same OpenClaw shell, its own AI fallback chain, a stronger engine on the other end of the leash) to test how the harness holds up when the model is sharper. Hermes, currently a visual-asset side-process here, is graduating into full autonomous agent development with its own dev loop. And the longer thread I keep wanting to pull on is putting an LLM inside an engine rather than in front of it: adventures with Unity MCP, where the model becomes a runtime collaborator instead of a chat endpoint. All on free tiers where they fit, paid where they do not, with the same lesson holding across every project on the shelf: the AI is the engine. The harness is the product.