June: Scaling per-team environments, the DevSecOps loop, and the "living knowledge" decay
June was about hitting the scaling limits of our single-environment Terraform setup, formalizing a shift-left DevSecOps pipeline to triage scanner noise, and confronting the human cost of the agentic rig we built over the last few months.
Terragrunt and per-team ephemeral environments
The AWS dev environments we wired end-to-end in Terraform back in April hit their breaking point. As we scaled to multiple teams requiring identical cloud environments, the boilerplate became unmanageable. I shipped a Terragrunt-only architecture on top of that prior Terraform work to spin up real, on-demand ephemeral environments.
The major unlock was moving to native Terragrunt Stacks. Instead of writing custom bash scripts to weave environments together, Stacks let us define a native dependency graph across terraform modules. This means we can orchestrate state across an entire environment natively.
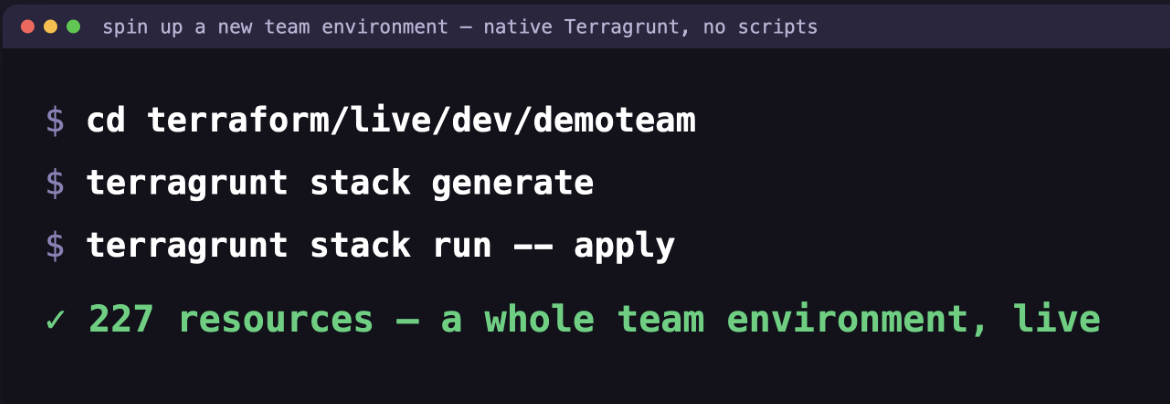
terragrunt stack generate & terragrunt stack run -- apply
This gives us real, on-demand environments spun up purely by Terragrunt. This isn’t just a proof-of-concept; it’s how we operate day-to-day. Environments deploy end-to-end with the API and UI fully healthy. Developers continuously spin up a fresh stack and validate it by running our core headed Playwright tests against it. These environments are cleanly decommissioned as soon as the development task concludes, or automatically purged after 48 hours of idle time. The entire apply → destroy lifecycle now runs flawlessly without any shared-resource conflicts or orphaned infrastructure.
Shift left and the DevSecOps loop
We formalized our vulnerability-remediation pipeline by wiring Claude to triage findings from GitHub Advanced Security (source) and Black Duck (binaries).
To build a true “shift-left” loop, AI makes the first pass to separate actual vulnerabilities from scanner noise. DevSecOps engineers then rate the findings by severity and effort, before Product Managers prioritize them directly into developer sprints.
The results were immediate. We dropped hundreds of noisy flags down to a dozen genuinely critical findings.
To keep everyone aligned, Jira acts as the single source of truth. A shared dashboard tracks these surviving vulnerabilities, cleanly labeled by risk and fix effort.
It was a sobering reminder that “shifting left” isn’t solved by writing better code or buying better scanners. True shift-left is achieved entirely through teamwork and cross-team collaboration.
The “living knowledge” decay
For the last three months, the goal has been pure agentic velocity: wiring up MCP servers, hooking Claude Code into our dev environments, and letting it run 6 to 8 concurrent terminal commands to scaffold infrastructure. It works brilliantly, but it comes with a quiet, compounding tax. When the AI abstracts the CLI away entirely, the engineers stop typing the commands.
This culminated in a very honest debate sparked by engineering leadership this month:
If we delegate the terminal to agents, we risk losing the “living knowledge” of our infrastructure.
I would rather keep Actual Intelligence strictly in the loop for when things inevitably break.
The critique is spot on. If an agent builds your production-parity environment by autonomously chaining jq, aws, and terraform, you don’t actually know how the environment was built—you only know the prompt you used to ask for it. The goal moving forward isn’t to slow the agents down, but to force them to over-document their CLI execution paths into handover files. We are treating agent sessions less like magic wands and more like junior engineers whose work must be auditable by a human who actually holds the pager.